
上海金畔生物科技有限公司代理New England Biolabs(NEB)酶试剂全线产品,欢迎访问官网了解更多产品信息和订购。
产品资料 – 用于二代测序的 NEBNext® 试剂 – 适用于 Illumina 测序平台/靶向富集
NEBNext Direct® 基因分型解决方案靶向富集试剂盒 收藏
货 号
规 格
价 格(元)
北京库存
上海库存
广州库存
成都库存
苏州库存
#E9530B-S
8 reactions
.00
无
无
无
无
无
Download:
- isoschizomers |
- compatible ends |
- single letter code
相关产品
NEBNext Direct® 基因分型解决方案样本制备试剂盒
概述
NEBNext Direct® 基因分型解决方案具有低成本高效益、高通量等特点,通过对靶基因测序进行基因分型,可广泛应用于植物、动物和人类。
NEBNext Direct® 基因分型解决方案将多重基因序列捕获富集技术与高效的二代测序相结合,从而为各种应用提供低成本高效益、高通量的基因分型。适用于 100-5000 Marker 范围,多达 96 个样本的预捕获结合双端检索引物,使得一次 Illumina® 测序,就可对 380 万个以上的基因进行分型。
产品描述
适用于几百到几千个 Marker 基因分型的理想解决方案
多达 96 个样本的预捕获降低成本并简化操作流程
加入双端检索引物和唯一分子标签实现测序效率最大化
通过独特的靶基因捕获富集技术,实现无与伦比的目标覆盖均一性
精密的探针设计,避免 Marker 丢失
仅需 1 天的实验流程,可自动化,极大提高样本通量
96 个样本的质控后 Reads
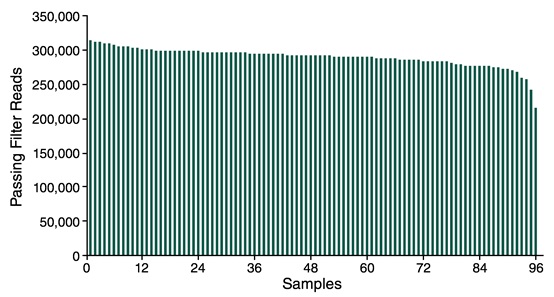
使用 SolCAP 公开提供的 2,309 个 Marker Panel 对 96 个番茄 DNA 样本进行富集,并结合 NEBNext Direct® 基因分型解决方案试剂盒做基因分型。图中显示了质控后的 Reads 数。每个样本起始量为 25 ng 纯化的番茄 DNA。样本加上标签标记后再进行杂交,文库在 Illumina® Miseq® 上测序,并设置程序:12 个碱基的唯一分子标签和 8 个碱基的样本标签用 Read 1 运行 20 个循环,目标基因用 Read 2 运行 75 个循环。
NEBNext Direct® 基因分型解决方案在 96 个样本中显示了相似的覆盖度
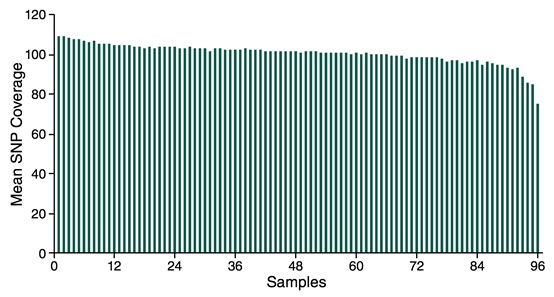
图中显示了 96 个样本 2,309 个 SolCAP Markers 的平均 SNP 覆盖度。每个样本起始量为 25 ng 纯化的番茄 DNA。样本加上标签标记后再进行杂交,文库在 Illumina® Miseq® 上测序,并设置程序:12 个碱基的唯一分子标签和 8 个碱基的样本标签用 Read 1 运行 20 个循环,目标基因用 Read 2 运行 75 个循环。结果表明:NEBNext Direct® 基因分型解决方案在 96 个样本中显示了相似的覆盖度。
NEBNext Direct® 基因分型解决方案对 96 个样本富集的特异性
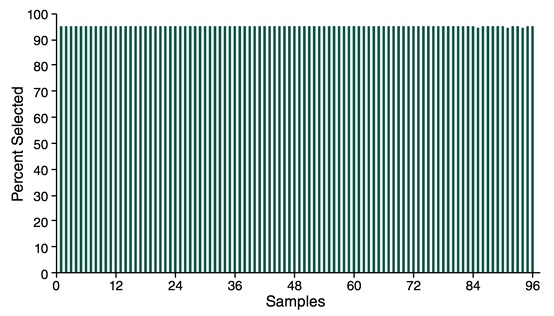
图中显示了质控后的 Reads 数比对到目标区域的百分比,表明 NEBNext® Direct 基因分型解决方案在 96 个样本中都显示出高度特异性。每个样本起始量为 25 ng 纯化的番茄 DNA。样本加上标签标记后再进行杂交,文库在 Illumina® Miseq® 上测序,并设置程序:12 个碱基的唯一分子标签和 8 个碱基的样本标签用 Read 1 运行 20 个循环,目标基因用 Read 2 运行 75 个循环。
单个样本中 2,309 个 Marker 的平均覆盖度
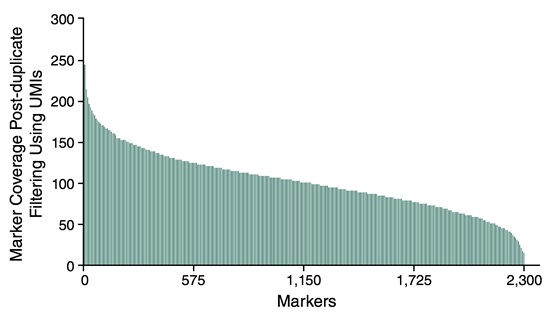
2,309 个 SolCAP Markers 覆盖度的柱状图显示了目标富集和覆盖水平的均一性,该结果足以进行基因分型。这些数据来自与其它 95 个番茄样本混合杂交后的一个番茄样本。样本起始量为 25 ng 纯化的番茄 DNA。样本加上标签标记后再进行杂交,文库在 Illumina® Miseq® 上测序,并设置程序:12 个碱基的唯一分子标签和 8 个碱基的样本标签用 Read 1 运行 20 个循环,目标基因用 Read 2 运行 75 个循环。